In this chart of cost per megabase of DNA sequence, an extrapolation based on Moore's Law has been added. What's wrong with this? It starts in 2001, the year of the human genome.

In 2001, only few animal genomes had been published (starting with worm in 1998). If I had to compare the human genome to a computer, I'd pick ENIAC. Moore's Law, however, was stated in 1965, some 20 years after the first "real" (i.e. Turing-complete) computers like the Zuse Z3 or ENIAC. When you go back, Moore's law doesn't hold anymore:
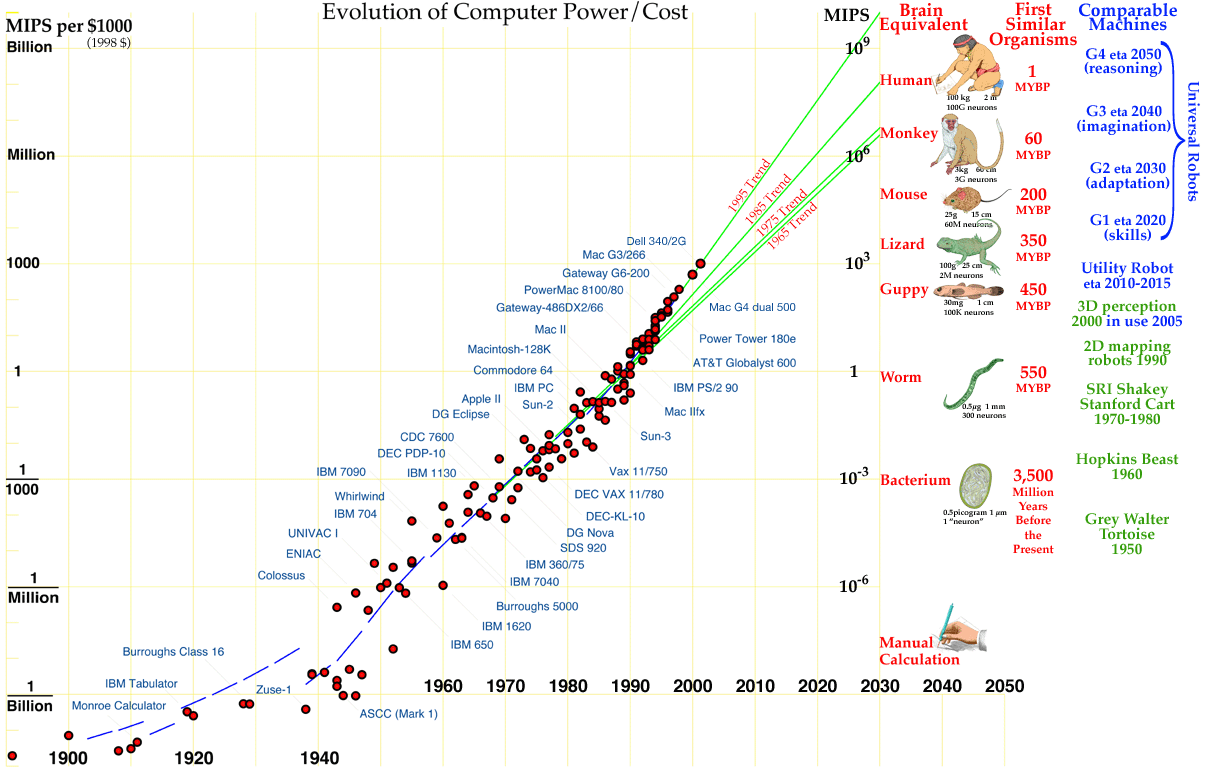 |
| Source: Hans Moravec |
With which rate will DNA sequencing progress? Perhaps the sharp decrease in sequencing costs between 2008 and 2010 is comparable to the transition from vacuum tubes to transistors, and Moore's Law will be followed from now on (extrapolating from three data points...). But perhaps we'll see more sharp decreases, and should overcome the desire to extrapolate using Moore's Law from arbitrary starting points.
(HT Deepak.)
No comments:
Post a Comment